Intelligent Semantic Caching for Video Surveillance Systems
Motivation
Traditional video surveillance systems face a fundamental challenge: vast amounts of footage are captured continuously, yet retrieving specific events requires manual review or keyword-based searching of metadata. This process is time-consuming, imprecise, and fails to leverage the semantic richness contained within video content.
Existing solutions typically rely on either computationally expensive cloud processing or limited edge-based object detection. Neither approach adequately balances the competing demands of real-time performance, semantic understanding, and natural language query capabilities.
Our framework addresses these limitations by combining edge computing efficiency with cloud-based semantic reasoning, enabling security operators to query surveillance footage using natural language like "show me when someone in a red jacket entered through the north entrance."
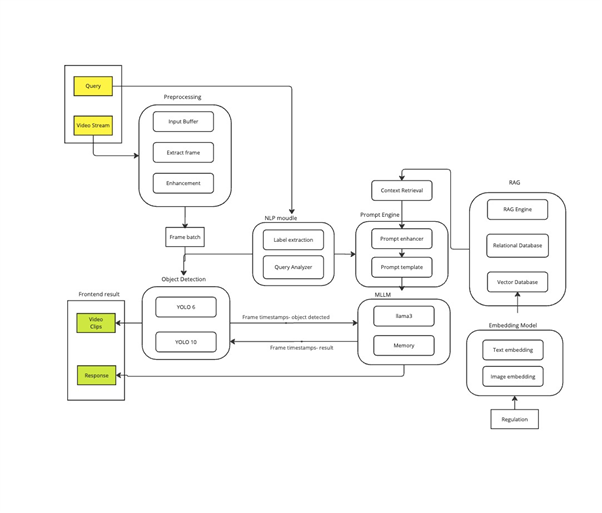
Architecture Overview
The system employs a three-tier architecture that distributes computational workload strategically across edge devices, local caching infrastructure, and cloud services.
Edge Layer: YOLOv10 models deployed using Oclea's Zeus camera edge devices to perform real-time object detection and tracking with SoM hardware acceleration. When significant events are detected (motion, person detection, unusual activity), frames are flagged for semantic processing. This acts as a lightweight first-pass filter, reducing bandwidth requirements compared to continuous streaming to a more expensive model.
Semantic Processing Layer: Flagged frames are processed through OpenAI's CLIP model to generate vector embeddings that capture semantic content. These embeddings encode visual concepts in a way that enables zero-shot classification and similarity search without task-specific training.
Query Layer: An oLlama-based LLM with RAG capabilities processes natural language queries, converting them into semantic search vectors that query the vector database using cosine similarity. Retrieved frames are presented with contextual summaries generated by the LLM.
Technical Implementation
The vector database utilizes Pinecone for high-performance approximate nearest neighbor search across millions of frame embeddings. Each embedding is stored with temporal metadata, camera identifiers, and object detection results from the YOLO layer.
The caching strategy implements intelligent frame retention based on multiple criteria:
- Semantic diversity: frames with embeddings distant from existing cached content
- Temporal significance: events spanning multiple frames or cameras
- Query frequency: content matching historical search patterns
- Novelty detection: unusual patterns identified through clustering analysis
The RAG pipeline augments LLM queries with retrieved frame metadata, enabling the model to provide contextually aware responses. For example, when asked about "recent deliveries," the system retrieves relevant frames and generates responses like "Three delivery vehicles detected: 2:15 PM at loading dock, 4:30 PM at main entrance."
Challenges & Limitations
Despite strong performance, several challenges emerged during deployment. Lighting conditions significantly impact CLIP embedding quality, with nighttime or low-light footage showing reduced semantic accuracy. We partially addressed this through adaptive preprocessing and embedding calibration.
Privacy considerations required careful system design. All semantic processing occurs within controlled infrastructure, and the system includes configurable privacy zones where detection is suppressed. Embedding anonymization techniques ensure that facial features cannot be reconstructed from stored vectors.
The LLM query layer occasionally generates overly confident responses when retrieval results are ambiguous. Implementing confidence scoring and uncertainty quantification improved reliability, though interpreting natural language queries remains an open challenge for edge cases.
Future Directions
Current work focuses on extending the framework's capabilities and addressing identified limitations:
- Temporal Understanding: Incorporating video transformers to capture action sequences rather than isolated frames
- Multi-Modal Integration: Adding audio analysis for events like alarms, breaking glass, or specific vocalizations
- Federated Learning: Enabling multiple deployment sites to improve models while preserving privacy
- Active Learning: Using operator feedback to continuously refine semantic representations
- Real-Time Alerting: Proactive detection of specified events through continuous embedding analysis
We are also exploring applications beyond security surveillance, including retail analytics, traffic monitoring, and industrial safety systems. The fundamental framework of edge detection, semantic embedding, and natural language querying proves broadly applicable to video understanding tasks.